GEAR-Seg: A Grounded Explainable Agent for Reasoning Segmentation and Data Engine
Grounded Explainable Agent for Reasoning Segmentation
College of Biosystems Engineering and Food Science, Zhejiang University, Hangzhou 310058, China
ZJU-Hangzhou Global Scientific and Technological Innovation Center, Zhejiang University, Hangzhou 311215, China
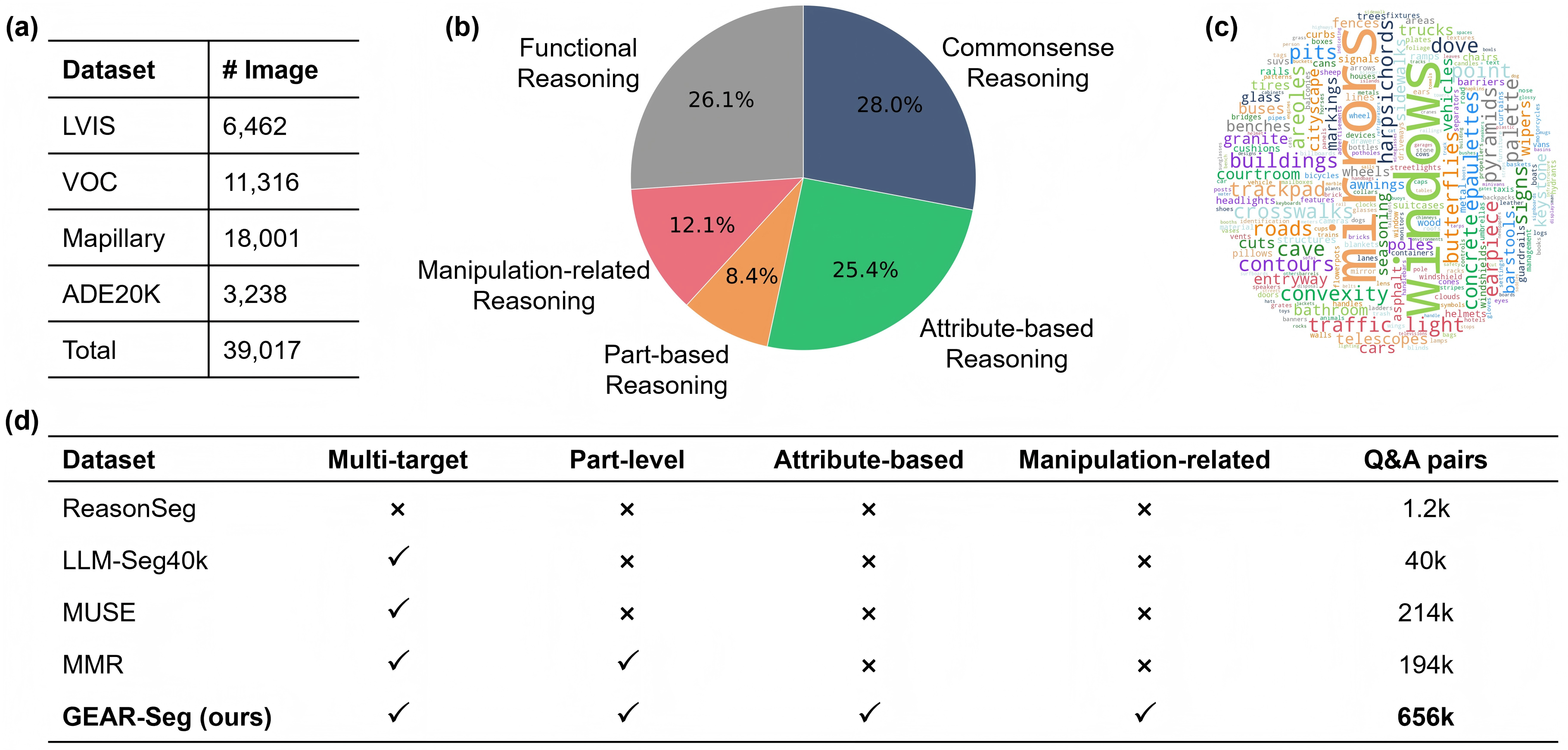
Figure 1: Overview of GEAR-Seg's multifaceted capabilities. Serving as both a zero-shot inference agent and a scalable data engine, it explicitly translates pixels into text to seamlessly support complex reasoning segmentation, dense referring segmentation, and fine-grained attribute grounding in long-tail domains.